
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- 파이썬
- 분산
- Blender
- 인공지능
- 공간적 자기상관성
- spatial autocorrelation
- PyCharm
- 트랜스퍼 러닝
- 심볼릭AI
- 옵시디언
- PostgreSQL
- Matrix
- 일러스트레이터
- 평균
- 머신러닝
- QGIS
- pgAdmin
- 공간분석
- Python
- 텍스트그림자
- Obsidian
- illustrator
- django
- 행렬
- 블렌더
- 일러스트
- ML
- 벡터
- 도형그림자
- 찰스 배비지
- Today
- Total
주석으로 채워가는 대학원생의 연구 노트
점 추정(Point estimation)의 개념 - 추론 통계, 모수, 점 추정, 추정량, 추정치의 개념 본문
점 추정(Point estimation)의 개념 - 추론 통계, 모수, 점 추정, 추정량, 추정치의 개념
밤샘노트 2025. 1. 28. 16:19

# 추론 통계란
추론 통계는 전체(모집단)를 직접 조사하지 않고, 일부(표본)를 통해 전체를 추정하거나 판단하는 방법이다.
예를 들어, 우리나라에 사는 모든 사람(모집단)의 키를 조사한다고 가정해 보자
- 모든 사람의 키를 측정하려면 막대한 시간과 비용이 들어 현실적으로 불가능하다.
- 대신, 일부 사람들(표본)의 키를 조사하고 그 결과를 이용하여 전체 사람들(모집단)의 평균 키를 추정할 수 있다.

# 모수(Parameter)란
모수는 모집단의 특성을 나타내는 값이다.
예를 들어,
- 모집단의 평균 : 모든 사람의 값을 합한 뒤 계산하는 평균
- 모집단의 분산 : 값들이 평균에서 얼마나 퍼져 있는지를 나타냄
- 모집단의 비율 : 특정 조건을 만족하는 비율
다시 말해, 모수는 모집단(전체)을 대표하는 숫자이다.
하지만 모집단을 전부 조사하기에는 시간과 비용이 많이 들기 때문에, 표본을 사용하여 모수를 추정할 수 있다.
# 표본을 이용한 추정
표본(일부)를 조사한 후 이를 이용하여 '모집단의 특성(모수)'을 추정하는 방법은 다음과 같다.
1. 표본 평균
- 표본에 포함된 값(예: 사람들의 키)을 모두 더한 뒤 표본의 개수로 나눈 값
- 예를 들어, 5명을 조사했는데 키가 160, 165, 170, 175, 180이라면,
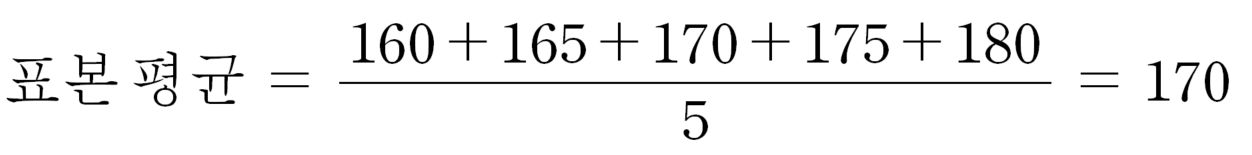
2. 표본 분산
- 표본 값들이 얼마나 흩어져 있는지를 나타내는 지표
- 예를 들어, 어떤 표본은 키가 비슷한 사람들로만 이루어질 수 있고, 다른 표본은 키의 차이가 큰 경우도 있다.
- 이러한 흩어진 정도를 분산으로 표현한다.
# 점 추정(Point Estimation)이란
점 추정은 표본 데이터를 사용하여 모집단의 모수를 하나의 숫자로 추정하는 방법이다.
예시 : 표본 평균 170cm라면 → "우리나라 사람들의 평균 키는 170cm일 것이다."라고 추정할 수 있다.
# 추정량과 추정치의 개념
추정량(Estimator)과 추정치(Estimate)는 헷갈리기 쉬운 용어이다.
이 두 용어에 대해 정확히 이해하고 넘어가자.
1. 추정량(Estimator)
- 추정량은 '추정에 사용하는 공식이나 방법(절차)'를 말한다.
- 예: 모집단의 평균(모평균)을 추정하기 위해 표본평균을 사용하는 경우, 표본평균을 계산하는 방법 자체가 추정량이다.
- 추정량은 값이 아니라, 계산하는 방법을 의미한다.
2. 추정치(Estimate)
- 추정치는 실제 데이터를 넣어서 계산한 결과 값이다.
- 예시: 5명의 키를 조사하여 평균을 구한 값이 170cm라면, 이 170cm가 추정치이다.
- 추정치는 특정 표본에서 계산된 하나의 값을 의미한다.
쉽게 말해,
- 추정량: "어떻게 계산할까?"라는 방법
- 추정치: "계산한 결과는 뭐야?"라는 숫자
# 왜 추정량은 확률변수일까?
추정량은 특정 표본을 바탕으로 (랜덤하게 선택되어) 계산되기 때문에, 표본이 바뀔 때마다 다른 값이 나온다.
예를 들어,
- 첫 번째 표본(10명): 평균 키 168cm
- 두 번째 표본(10명): 평균 키 172cm
- 같은 모집단에서 표본을 추출했지만 결과가 다르다.
따라서, 추정량 자체는 매번 달라질 수 있는 확률변수로 간주된다.
# 표본평균과 표본분산
추정량의 대표적인 예로 표본평균과 표본분산이 있다.
이 둘은 각각 '모평균(모집단의 평균)'과 '모분산(모집단의 분산)'을 추정하는 데 사용된다.
1. 표본평균(모평균의 점 추정량)
표본평균은 표본의 값을 모두 더한 뒤, 표본의 크기로 나눈 값이다.
이를 사용하면 모집단의 평균을 추정할 수 있다.
그러나 표본마다 값이 다르기 때문에, 표본평균 자체는 확률변수로 간주된다.
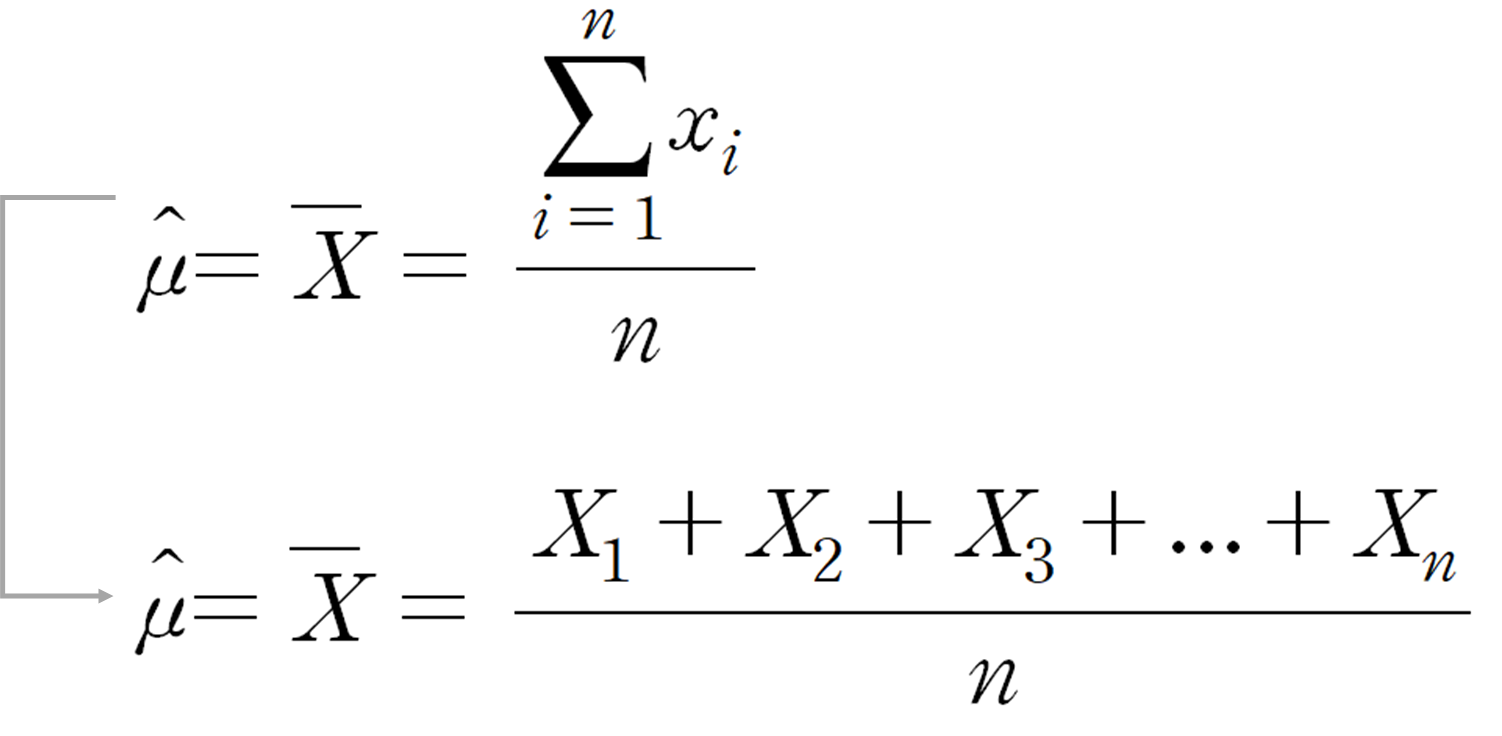

2. 표본분산 (모분산의 점 추정량)
표본분산은 데이터가 평균에서 얼마나 퍼져 있는지를 계산하는 방법이다.
이를 통해 모집단의 분산(모분산)을 추정할 수 있다.


# 점 추정이 중요한 이유
점 추정은 모집단(전체)를 이해하기 위한 중요한 첫 단계이다.
그러나 표본은 모집단의 일부이기 때문에 항상 오차가 존재할 수 있다는 점에 주의해야 한다.
다음 포스팅에서는 점 추정하는 방법과 오차를 줄이는 방법(신뢰구간, 가설 검정 등)에 대해 자세히 다루도록 하겠다.
# 참고자료
이번 포스팅에서는 아래 사이트를 참고하여 정리하였습니다.
저작권이나 기타 문제가 있을 경우 알려주시면, 즉시 검토하고 수정하겠습니다.
https://product.kyobobook.co.kr/detail/S000000453694
고급통계분석론 | 이희연 - 교보문고
고급통계분석론 | 고급통계분석의 이론과 실습을 병행하여 소개하는 『고급통계분석론』. 이 책은 통계이론과 원리에 대한 기초를 확립한 후 통계분석 방법을 배우도록 유도한다. 연구 목적에
product.kyobobook.co.kr



